For all the audio engineers out there, be you live sound, studio producer, or even integrator, you are all aware of the importance of using compression. It might just be the 2nd most valuable tool in your signal processing arsenal (the first being your ears, without which it would be hard to tell anything). This will probably be a redundant subject for some, but I still find that the reasoning behind why compression is so important tends to get left out when the fundamentals are being taught.
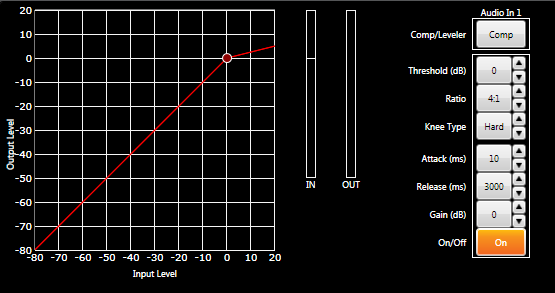
Before we get involved in the reasoning behind the importance of compression, let’s take a look at what a compressor actually does. Given the sheer numbers of audio equipment manufacturers and trainers in the world, there are probably as many explanations as to how it works as there are people offering up an opinion. I’ve heard a lot of these explanations, but I’m going to try and give one that I heard when I first started that I always believed put it most simply. The compressor is a signal processor that takes signal and decreases the distance between the peaks and valleys of a sound wave. As we know, the greater the distance between the peak and valley of a sound wave the louder a signal will be. With a compressor, we can set a specific threshold that allows us to say that any audio above this point should be turned down by a specific ratio. This allows us to keep the level much more consistent and knock down the loudest signals in volume so that they don’t overpower us and are closer to the softer levels. By knocking down the loudest parts of the sounds we can set the fader and trim levels of a signal higher. For example, if we were working with a paging microphone we would need to assume that several different people might be speaking into it. Each person is going to have a different level speaking voice. We would need to make sure that the softest voice would be heard with enough volume to get the message across. The louder voices will be able to broadcast a message with greater ease, but if we set up the input gain structure for a softer voice we would run into distortion that could make the voice unintelligible. And that is where the compressor plays the vital role. By allowing us to set up the input gain structure for a lower level signal we are able to ensure it will be heard clearly, and with compression we can make sure that the louder signals will not distort, creating a happy middle ground and keeping the levels much more consistent.
When applying compression in music situations, though, there is an additional level of complexity. As sounds have a tendency to be inconsistent in their volumes (which we call dynamic range) we have to be careful that as we apply compression to them we do not process them to the point where the audio can’t have any variance between the softest and loudest points. By using compression to control the change in dynamic range of a sound, we can stop reaching for the faders to constantly balance the signals in the mix and give ourselves greater headroom in the overall mix. This is something that takes time and practice to understand where to set a specific threshold for where the compression should start, where to set the ratio to make sure you are adjusting the output level correctly, and still keeping some flexibility in the dynamic range. Additionally, this is not a cookie cutter setting. There can be general guidelines for where you can start this process, but as no person will play an instrument in exactly the same way, or sing a phrase in the same precise manor, each time you apply compression should be treated as an independent instance as you’re learning how to master this tool.



